Manage data pipeline
Create data pipeline allows us to define ETL pipelines that creates or updates event logs at a defined schedule. At any point when creating the ETL pipeline, we can save the pipeline. This allows us to edit the pipeline at a future time. To save a pipeline, click the save pipeline icon in the top-right corner of the Data Pipeline Creation window.

We’d be prompted to enter the pipeline name.
We can also save a pipeline and exit the pipeline. Click the save & exit pipeline icon.
After saving a pipeline or successfully scheduling it, we can manage the pipeline to discover its status, edit the pipeline, stop the pipeline schedule, share the pipeline, or delete the pipeline.
To manage the saved or scheduled pipelines, click Data > Manage pipelines in Portal.
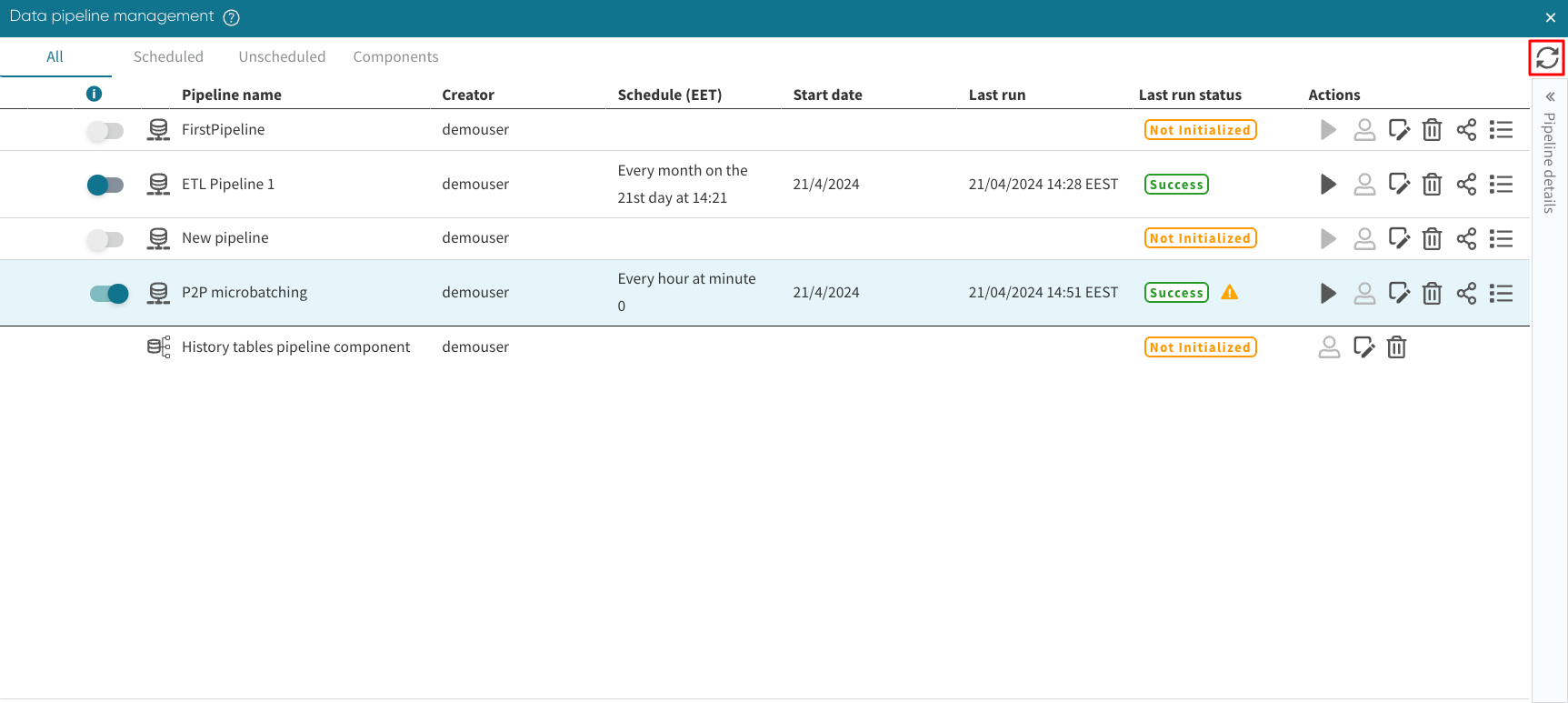
The Data pipeline management window appears, displaying all the scheduling-related details next to the pipeline name: time/frequency of loads, status, last run.

Note
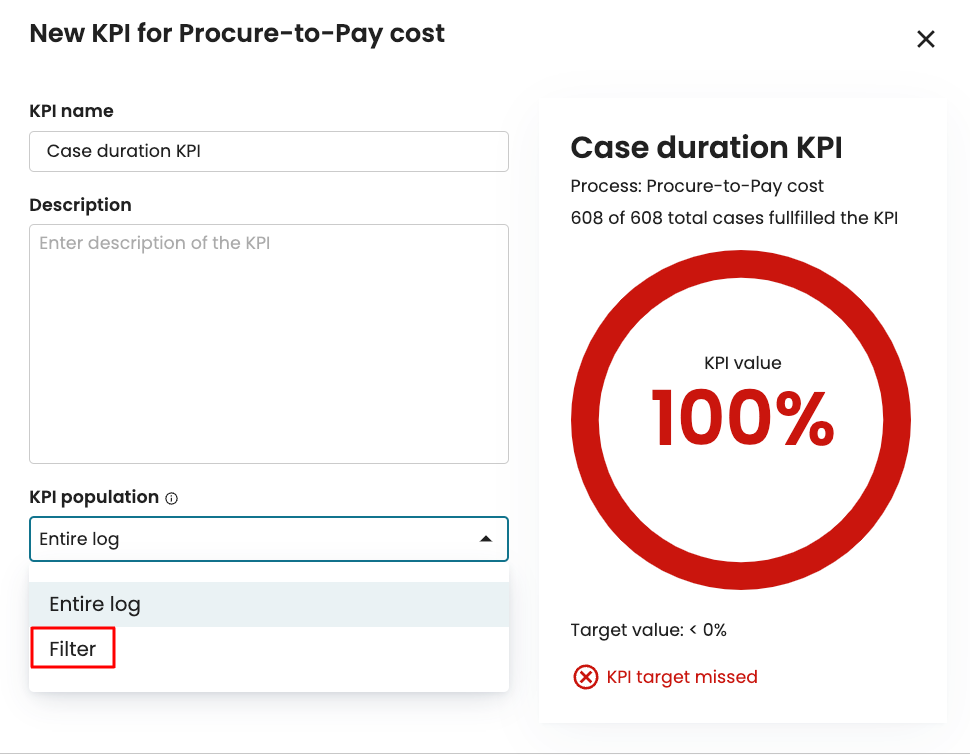
By default, the window shows all the pipelines. To see only the scheduled pipelines, unscheduled pipelines or pipeline components, click on the corresponding tab.

We can unschedule a scheduled pipeline by moving the pipeline activation slider next to the pipeline name. When the slider is toggled to the off position, the pipeline would not run when it reaches its scheduled time.
Similarly, we can schedule the pipeline by toggling on the switch.
The Data pipeline Management window also informs us about the last run status. The status run could be Success, Failed, Not initialized, Queued or Runnning.
Success: The scheduled pipeline run was successful.
Failed: The system could not successfully run the scheduled pipeline.
Not initialized: The pipeline was saved but not scheduled.
Queued: The pipeline job is currently in a queue waiting to run.
Running: The pipeline is currently running.
Note
When a pipeline is scheduled from an S3 folder, and there are no unprocessed micro-batches in the S3 folder at the start of a pipeline run, the pipeline is marked as “Success” but with a warning icon  . The hover-over message in the pipeline manager indicates that there were no micro-batches to be processed by this pipeline run.
. The hover-over message in the pipeline manager indicates that there were no micro-batches to be processed by this pipeline run.
To view the details of all previous runs, click the menu icon.
Note
The final status of the pipeline run might be either Success or Failed. When the status is Failed, system could not run the scheduled pipeline successfully. We can learn more about the cause of the failure by hovering over the “Failed” status.
If we wish to trigger a pipeline to run now, we can click the play icon 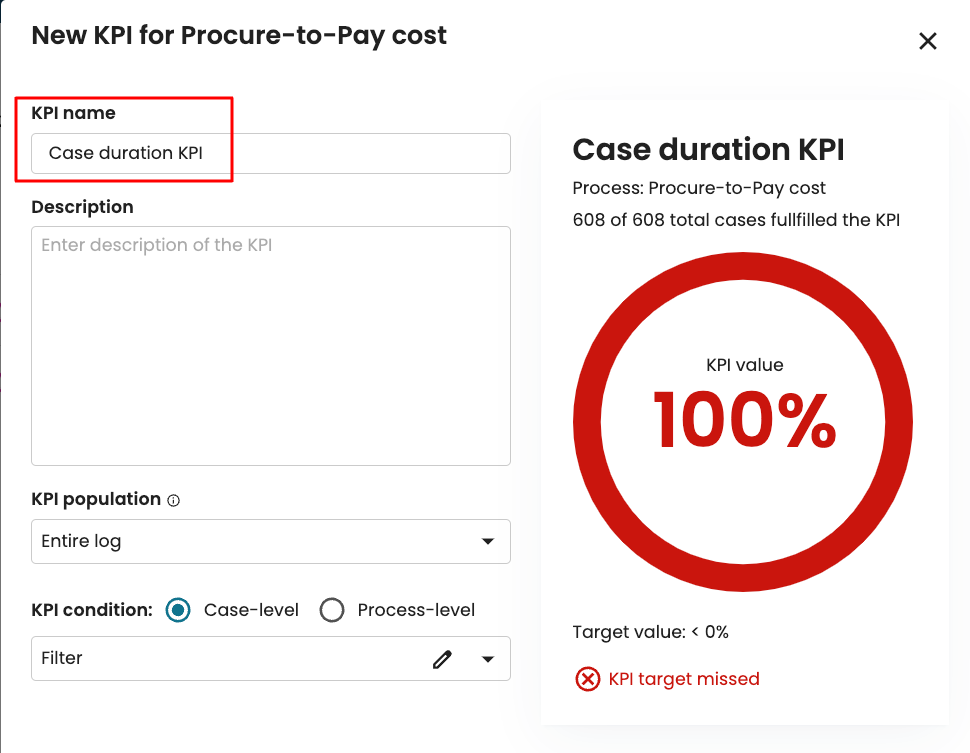 .
.
We can also edit a pipeline by clicking the edit icon 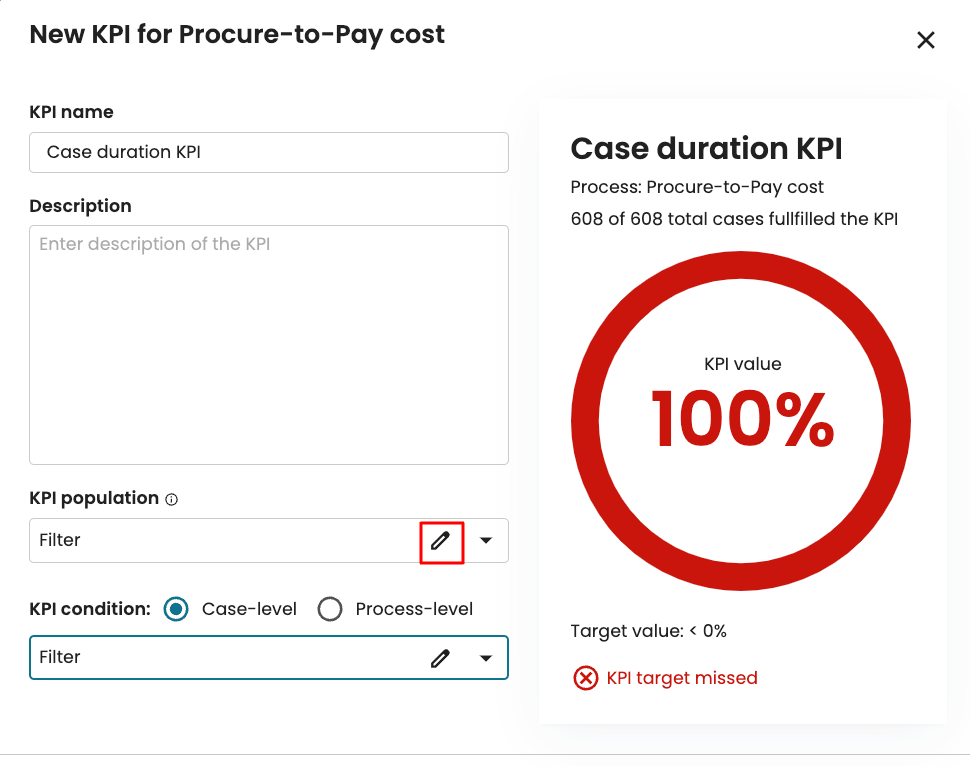 .
.
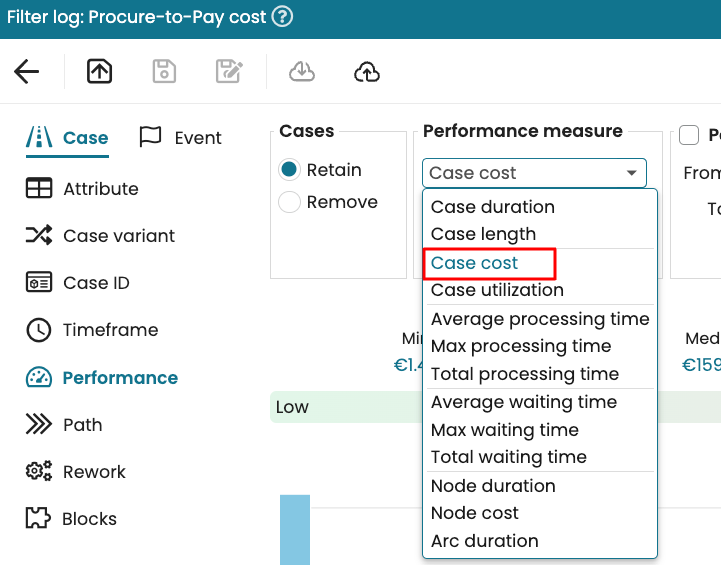
This redirects us to the Data pipeline creation window where we can edit the Extract, Merge, Transform or Load tab of the pipeline.
Warning
When we edit a scheduled pipeline, the pipeline becomes unscheduled. After editing, ensure to schedule the pipeline again by toggling on the pipeline activation slider.
To delete a scheduled pipeline, click the bin icon 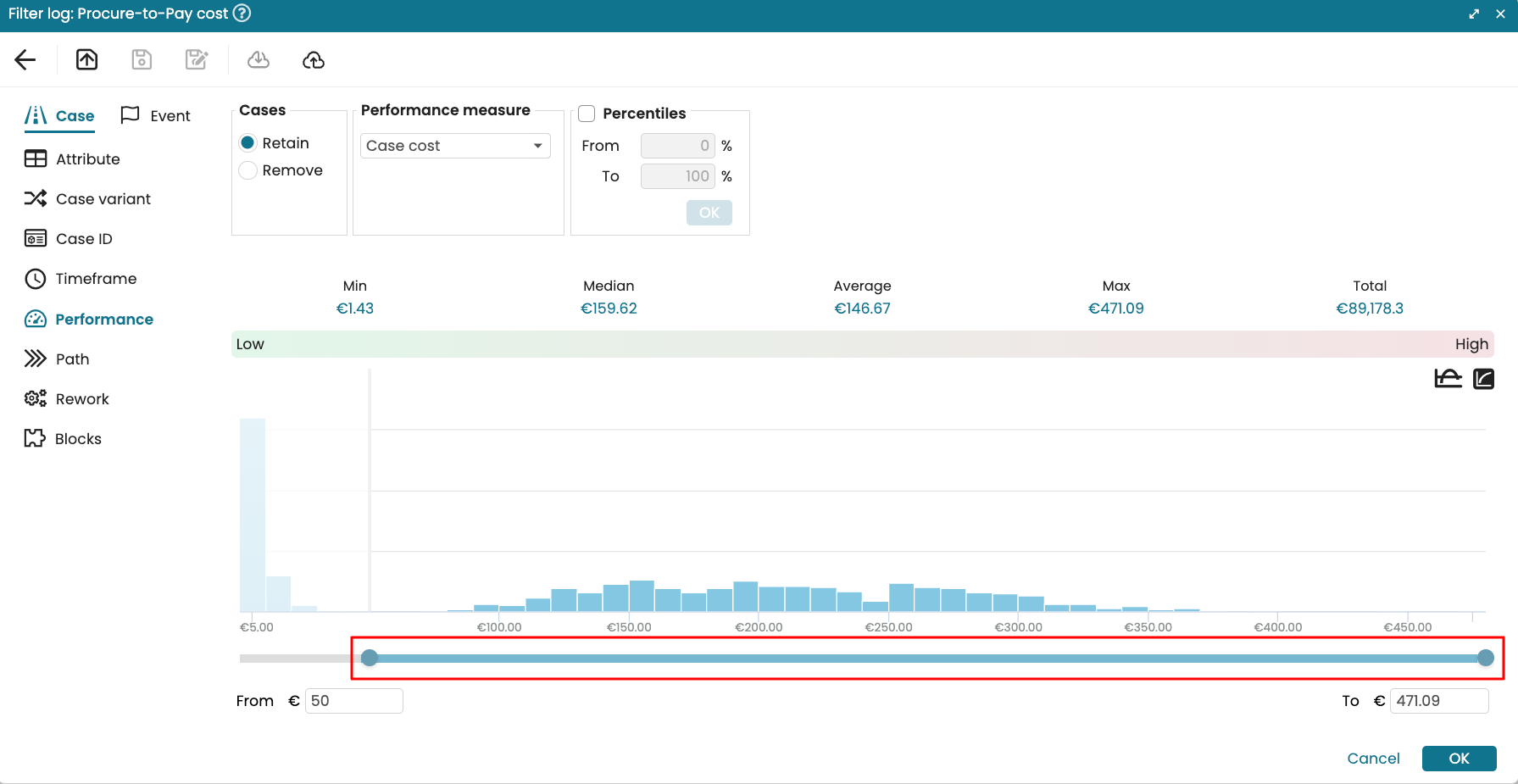 .
.
We can share a data pipeline with other users by clicking on the share icon  .
.
Note
When we share a pipeline, and the pipeline is being edited by the shared used, we cannot edit the pipeline. To learn more about sharing a data pipeline, see Share data pipeline.
We can also refresh the window to get the latest pipeline management information.
To refresh the window, click the refresh icon  .
.